포인트라는 도메인 혹은 서비스는 일반적인 온라인 플랫폼이라고 하는 범주에서는 어디에서나 쓰이는 데이터 입니다
이 데이터에 대해서 대량의 포인트 적립/사용과 같은 비즈니스를 처리해야 하는 경우가 생길 수 있고 CRM 파트에서는 이 포인트를 주로 처리하는 부서로 Mauve 에도 대량 처리 기능에 대한 needs 가 있었습니다
FnC 만의 임직원 전용 포인트의 경우도 약 1000여 명이 2종류의 포인트를 적립해야 했기에 실시간으로 약 2000건의 json data를 처리해야 합니다(예약 적립 기능이 생겨서 전날 처리는 가능)
여기서 발생 된 처음 장애 과정과 현재 메시징 시스템과 같은 비동기 처리와 코루틴과 같은 서버 자원의 최적화 관점의 처리 방식의 도입까지 그 내용을 정리 하려고 합니다
성능 혹은 데이터의 처리량에 대한 최적화 경험이 거의 없어 전체적으로 큰 그림을 그리는 것 부터 시작되었고 성능 수치와 관련된 접근을 어디 어느 부분을 건드려야 하지? 내가 아는 지식과 모르는 것에 대한 분리와 활용은 어디 부터 시작해야 하지? 혼란스러웠던 초기화 과정부터 다뤘습니다
특히 다양한 테스트를 해야 하는 실험 환경이나 수치의 분석이 어려웠었기에 결과에 영향을 미치는 변인들인 독립변수와 종속변수들의 설정과 변경에 대한 다양한 테스트 시나리오를 세우는 것도 어려웠습니다
먼저 다양한 에러 메시지들을 만나면서 아래와 같은 용어들이 나왔습니다
- (데이터베이스) 동시성 제어 처리
- (데이터베이스) 커넥션 풀 부족
- (어플리케이션) 힙 메모리 부족
- (어플리케이션) 요청 처리 시간 최소화
- (서버) 최대 활성 쓰레드(Core) 수
- (서버) 확장과 축소 가능한 분산 환경 구조
아래 그림은 최범균이라는 개발자가 유투브에 올린 서버 성능올리기 라는 내용에 있는 그림입니다
위 관점과 비슷한 접근이고 내용도 길지 않아 내용 전체를 보셔도 좋을 것 같습니다

그리고 시스템을 구조화하면서 병목 구간이 될 수 있는 부분을 인지하고 처리 속도에 영향이 있는 이유를 추측할 수 있는 가설들이 필요 했습니다
데이터 흐름을 영역으로 구분하기 위해 아래와 같은 임의의 그림을 그렸습니다
- 어플리케이션 구조가 복잡한 부분은 이벤트 스토밍을 통해 표현했었습니다 (복잡하다는 것은 단일 책임의 원칙을 위반할 여지가 많기 때문에 성능 과는 별개로 유지보수를 위해 분리가 필요한지 고민해봐야 합니다)
- 네트워크 구간에 따른 적립 비즈니스 도식화
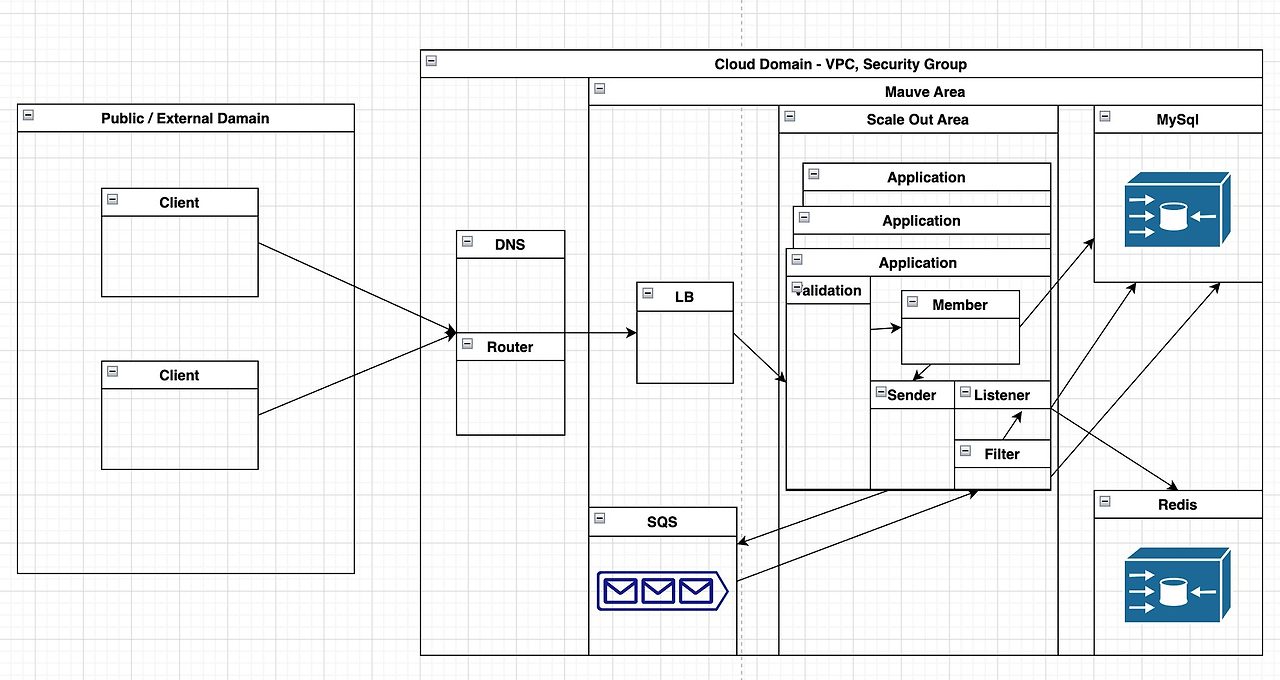
즉 위에서 구분한 서버 / 어플리케이션 / 데이터베이스 간 분산되어 있는 구조이고 고려해야하는 요인들을 그룹화 해봤습니다
- 정량적인 리소스
- Core(쓰레드) 수
- 분산서버(Pod) 수
- 클라이언트에서 보내는 1회 요청 데이터 수(100~500,000)
- 클라이언트에서 보내는 반복 요청 수(1~5,000)
- 네트워크 대역폭(용량) - LB 의 최대 허용 용량 (100MB)
- DB connection pool / Tomcat thread pool 최대치 설정
- 정성적인 리소스
- 처리시간을 줄이기 위한 불필요한 서버 로직 개선
- 비동기 처리를 위한 메시지 시스템 사용
- 메시지 수신 워커에 대한 분리 고민
- 동시성 처리를 위한 쓰레드/코루틴 사용
- 대용량 데이터 처리를 위한 bulk insert 고려
정확히 통계적인 접근법은 아니지만 실험계획에 있어 종속변수 Y 와 독립변수 X 로 검증하고자 했습니다
종속변수 Y1 은 TPS 즉 초당 처리횟수가 되며 요구사항에 부합하는 최대로 처리 가능한 데이터의 총량이 됩니다
종속변수 Y2 은 응답시간(Response Time) 이 되며 일정량을 처리하는 데 빨리 응답할 수 있는 값을 도출해야 합니다
Y1과 Y2는 독립변수에 따라 상호 연관성이 있을 수 있고 최대 처리량이 많으면서 빨리 응답가능한 수치가 필요했습니다
두 개의 값에 대한 명확한 요구사항은 있었고 그 부분에서 최적의 조건과 구조를 찾아야 했습니다
요구사항은 양과 속도로 나뉩니다
최대량 - 캠페인 처리 기준으로 1,000,000 ~ 2,000,000 건의 일시적인 요청을 처리할 것
속도 - 최대량 기준으로 30분 이내로 처리가 가능할 것
이런 부분을 토대로 여러번의 실험을 했고 이에 상응하는 가설 들을 세웠습니다
가설 1. 최대 개수를 빠른 시간내에 처리하기 위해서는 최소 회수로 최대량을 처리해야 한다 (효율성의 관점)
- 고려할 것 : bulk insert, batch process, max array request, min thread/connection pooling, max network bandwidth, connection timeout
- 논리적인 명분 1. 클라이언트에게 편리한 사용자 경험을 제공 하고 싶음 (최소 요청의 횟수의 경험)
- 논리적인 명분 2. 반복 요청에 의한 예외 핸들링시 원자성의 원칙을 쉽게 처리 할 수 있어야 함(All or Nothing)
- 논리적인 명분 3. bulk/batch application 으로서 처리한다면 대용량 처리를 위한 API 로 처리 가능(DB 처리 시간 최소화)
- 논리적인 명분 4. application 설계상 sender 와 listener 가 분리 되지 않았으므로 다른 API 와 영향도를 최소로 하기 위한 서버 가용 리소스의 최소 사용 (min thread/connection pooling)
가설 2. 분산 처리가 가능하고 스케일 아웃이 가능하므로 가장 빨리 처리하는 방식 즉 응답시간 최소화를 만든다 (최소 시간의 관점)
- 고려할 것 : effective insert, effective array request, effective thread/connection pooling, effective server(pod) count, latency time, processing time, exception handling
- 논리적인 명분 1. 실패에 대한 100% 보장을 할 수 있다면 클라이언트의 사용자 경험이나 예외 처리에 대해 고민할 이유가 없음 (Dead Letter Queue, Guarantee/Validation Processing)
- 논리적인 명분 2. 스케일 아웃에 대한 부담이 스케일 업 보다 적음 (Increase Worker)
- 논리적인 명분 3. 중간에 메시지 큐를 사용해서 완충 장치를 뒀기 때문에 큐로 넣는 Latency Time 만 고려하면 됨 (Fast Response)
- 논리적인 명분 4. 다른 API 와 같은 네트워크 구간을 사용 중이기 때문에 최대 용량을 사용할 수 없고 모든 자원을 적립 비즈니스에 올인 할 수 있는 것이 아니기 때문에 최소 자원의 최대 효율이 필요 함
- 논리적인 명분 4. 막상 테스트 해보니 pooling 사용에 대한 반납이 빠르다면 pool 의 총량에 대해 고민할 이유가 없음 즉 반납 못하고 오래 붙잡는 pool 사용이 문제이지 pool 자원은 최대한 많은량을 빨리 사용하는 방법을 추구해야 함
크게 2가지로 구분 했고 전체 구조상 병목이 될 수 있는 부분이 추가로 있습니다
- Mysql / Redis 에 대한 단일 엔드포인트로 (Read/Write) 동시 처리에 대한 대기가 생길 수 있음(분산 데이터베이스 환경이 아닌 부분)
하지만 고려할 부분이 더 있었는데요 현재 시스템 구성이 저 위의 가설을 증명하기에 적합한 모델인지에 대한 판단도 필요했습니다
Application 에서는 Validation 말고도 신규 Member 정보일 때 추가 처리와 Queue 연동에 의한 Sender 와 Listener 에 대한 처리를 동시에 해야 했습니다 즉, 하나의 서버(Pod) 자원에서 하나의 Request 를 처리하기 위해 하나의 Tomcat(Servlet) Thread 로 처리할 수 있는 것이 아니라 Queue 처리로 인한 Listener Thread 도 안정적으로 확보가 필요했습니다
요청 비용에 대해 계산을 해보자면
One Request = Servlet Thread + Validation Processing + Member Processing + Sender Queue Connection + Unique Message Processing + Listener Thread + Mysql Connection + Redis Connection + Cache Processing
최소 2개 이상의 Thread 가 필요하며 4번의 비즈니스 처리가 필요하고 3번의 Connection 처리/반납을 해야 합니다
무거운 요청의 판단 기준은 잘 모르겠지만 대용량 처리를 하는데 있어 복잡한 모델에서 고민할 부분인지도 고려해봐야 했습니다
이 부분에 대해서 경험적인 도움을 얻고자 회사 안/밖에서 다양한 대량 처리의 형태를 조사해봤습니다
- Braze 라는 서비스에서는 csv 파일을 통해 100MB 까지 처리 가능
- Braze 라는 서비스에서는 REST Call 은 array limit 75 건 / 분당 50000 request limit
- 분당 max 처리량 : 3,750,000 건
- Game 회사의 아이템 대량 지급 처리에서는 REST Call 제한은 1 Request / array limit 1000 건
- Web API로는 DB 입력만이 목적이며 따로 Game Server 의 Worker 가 동작해서 케릭터 창고로 아이템 셋팅 후속 프로세스가 있음 (주기적으로 폴링하면서 셋팅할 데이터가 있는지 확인하는 Worker 가 있어서 TMS 의 동작방식과 비슷? 한 부분이 있어 보임)
- DB 입력시 Stored Procedure 를 통해 Bulk Insert 처리 됨 (트랜잭션 단위가 1000건 단위)
- Braze 처럼 분당 혹은 횟수의 제한은 없었고(오직 내부 서비스로 사용/게임이 인기도에 따라 최대값에 대한 운영적인 변수가 적어 보임) 3,000,000 처리를 하려면 1000개씩 3000번 보냄 (더 적은 횟수로 총량 처리 가능)
- N 사 커머스 쪽에서 REST 처리 기준 단일 array 500 * 2000 반복 횟수로 1,000,000 건 기준 2~3 분 처리 됨
- 카프타 파티션 30 / 컨슈머 30 운영 기준
- 디비는 분산 디비를 사용
문제 정의부터 가설 설정 및 다양한 변인들에 대해 고려가 된 것 같습니다
실제 사례까지 보면 현재 코오롱 비즈니스에서 1,000,000 ~ 2,000,000 만건의 데이터의 REST Call 처리가 불가능한 부분으로 보이지 않습니다 (N사의 경우 JPA 까지 사용)
위의 긴 과정이 있던 부분은 가설 즉 종속 변수에 영향을 미치는 독립변수에 대한 부분과 구조는 어떻게 설계해야 하는가? 이런 물음이 있었기 때문입니다
고려해야 하는 부분들이 많았기 때문에 단순화 해서 생각하기 위해서는 하나의 공식같은 부분이 필요했습니다
최범균 개발자가 위에서 제시한 서버 성능에 대한 관점으로 도출했습니다
예상 처리 수(Y1) = TPS(초당 처리량) = 처리한 트랜잭션 개수 / 처리시간
응답시간(Y2) = 대기 시간 (Latency Time) + 처리 시간 (Processing Time)
결국에는 아래와 같은 식으로 수렴됩니다 (정확한 선형 방정식으로 해석하기는 무리가 있고 변수를 식으로 나타낸 해석)
y = k0 + a1x1 + a2x2 + a3x3 + a4x4 + ... + an*xn
y : 최대 처리량 (빠른 응답속도를 내포)
x1 : 클라이언트 요청 개수 / a1 : 클라이언트 반복 회수
x2 : 네트워크 대역폭 용량 / a2 : 네트워크 구간(깊이)
x3 : 분산서버 의 스케일 아웃 수 / a3 : 서버의 core / memory 와 같은 리소스
x4 : 어플리케이션의 로직 처리 속도 / a4 : 어플리케이션 로직 수
x5 : Queue 로 전송 속도 / a5 : Sender 개수
x6 : Listener 수신 속도 / a6 : Listener 개수
x7 : 부하 처리기에서 책정한 정책 (Gateway)
x8 : tomcat thread pool 개수
x9 : hikari connection pool 개수
k0 : 분산 처리에 대한 자신감 + 분명히 나중에 발생될 장애 처리의 신뢰도
여기서 제가 조작가능한 변인이 있고 거의 고정값에 가깝거나 인프라 구조를 바꺼야 하는 변인들이 있기 때문에 요인 분석을 통해 유사 항목 끼리 묶어서 실질적으로 제어한 항목에 대해서만 고려합니다
y = (a1x1 + a4x4 + x5 + x6) + (a2x2 + a3x3 + ... + an*xn) + k0
x1 : 클라이언트 요청 개수 / a1 : 클라이언트 반복 회수
x4 : 어플리케이션의 로직 처리 속도 / a4 : 어플리케이션 로직 수
x5 : Queue 로 전송 속도
x6 : Listener 수신 속도
이제부터는 위 4개의 관점에서 개선되고 변경된 부분에 대해 정리합니다
첫 번째로 여러개의 분산서버가 하나의 Mysql에 접근하면서 동시성 문제가 발생되었습니다
Mauve 에는 회원의 메타 정보가 없기 때문에 기본적으로 요청 데이터에 의존합니다
나중에 모벤저스에서 회원이 어떻게 발전될 지 모르겠지만 일단 요청 값을 가지고 포인트를 처리 가능한 회원인지 판단하기 위한 Table에 Insert 를 진행합니다
Application은 분산된 구조이고 초기 설계에서는 Listener 에서 하나하나 처리를 했습니다
SQS 에서 App으로 전송이 될때는 FIFO 로 순서 보장이 되지 않는 Queue 이기 때문에 요청에 입력된 순서대로 Insert 된다는 보장이 되지 않습니다 (SQS 에서 서버로 받는 데이터는 중복 입력도 가능해 처리해야하는 Filter 가 있습니다)
FnC 임직원의 경우 2가지의 포인트로 회원 정보가 2번 중복되어 전송이 되었기에 이를 받아 들이는 Listener 에서는 순서가 보장되지 않는 상황에서 동시에 회원 정보가 Insert 될 확률이 있습니다 즉 DB의 Unique 제약 조건 위반에 걸릴 수 있는 동시 Insert 될 수 있는 상황이 만들어 집니다
문제정의 : Member Table에서 동시에 동일 정보로 Insert 되는 상황에 Unique 제약 위반이 발생
해결방법
해당 부분은 Member Validation을 위한 Setting 값이기 때문에 Queue 로 전송하기 전에 처리하는 형태로 순서를 변경했습니다 (Json Array 순서는 보장되고 로직 처리시 distinct 로 중복을 제거 해서 처리)
추가 문제 발생 가능성
Request 를 처리하는 Application 부분도 분산되었기 때문에 Client 가 동시성 처리를 해서 한번에 여러번을 보내게 되면 Listener 에서 발생 된 부분이 Service Layer 에서 발생될 여지가 있음
앞에 LB을 통해 App으로 Push 되는 부분과 SQS를 Pull 하는 근본 차이가 있어 발생 가능성이 매우 낮을 것으로 예상되고 Client 에서 For loop 와 같이 순차적으로 요청을 보낼 경우 네트워크 지연 차이가 없다면 거의 없을 것으로 예상 됨
다만 회원에 대해 무조건 적인 수용을 받기 때문에 처음에 잘못 입력이 되어 버리면 그 데이터에 대한 보증이 어렵습니다. 즉 회원으로 넣는 것은 후속 처리에 대한 확인을 위한 것이지 처음에 잘 못 넣었다면 이 부분에 대해 검증이 어렵습니다 (수기로 확인 필요)
회원에 대한 Owner Service 가 있어서 핵심데이터로서 관리가 필요해 보입니다

문제가 모두 사라진 상황에서 처음 테스트를 했을 때 Sample data 는 FnC 임직원 데이터를 사용했을 때 2000건으로 시작했습니다
이제는 테스트 환경이 매우 중요해지는데 로컬(맥북 단일) / 스테이지(분산 Pod) 서버 간 분산환경이라는 큰 차이가 있습니다 즉, 처리기로서 서버 하나에 대한 성능만이 측정되어 실제 운영환경을 대변할 수는 없습니다
즉 부하 테스트만을 위한 환경이 따로 구비되어 있지 않다는 문제에 직면합니다
사실 스테이지는 기능 테스트가 아닌 운영 배포 전 고정된 테스트 환경으로서 사용하는것이 권장되어 보입니다 (특히 다른 파트나 다른 서비스와 결합된 환경인 경우 or QA 조직을 위한 환경이 따로 구비된 경우)
로컬에서는 6코어(HT) 12쓰레드로 되어 있지만 전적으로 테스트에 모든 리소스를 쓰고 있는것이 아니기 때문에 로컬에서 성능을 신뢰하기는 무리가 있는 부분도 생깁니다
이 부분으로 인한 여러 테스트를 진행해도 해석이 어려워서 최종 도출에 어려움이 있었습니다
테스트를 어떻게 해야 부하/기능/통합/시나리오 등등 다양한 케이스를 만들어내는 부분이나 부하 발생기도 필요한 부분에서 어떻게 해야 할지는 꾸준히 고민할 부분으로 보입니다
결론적으로 얘기하면 아래의 그림과 같은 상황을 두고 테스트 를 해야 합니다

클라이언트에서 병렬 처리가되어 한번에 동시 요청을 보낼 경우 For Loop에서 하나 하나 응답 후 요청 하는 것보다 더 빠른 처리가 되나 반복 요청에 대한 Erorr Handling 을 어떻게 할지 Retry 전략을 클라이언트에서 생각해야 할것 같습니다
가장 먼저 맞닥뜨린 병목구간은 SQS 에서 넘어온 단일 포인트 정보를 Listener 에서 처리하는 시간이 매우 오래 걸렸습니다

Sender 와 Listener 가 하나의 App에서 처리하고 이 때문에 처리할 수 있는 Thread 자원 자체도 최소 2개 이상이 소모 됩니다 그리고 SQS, MySql, Redis 들과 Connection 을 만들어서 동기적으로 처리하기 때문에 처리시간도 절대적으로 오래 걸릴 수 있습니다
현재 구조에서 Sender <-> Worker 간 분리가 안되는 상황에서는 하나씩 단건 처리하는 입장에서는 Application 성능이 좋아야 더 많은 양을 처리할 수 있는 부분입니다 즉 Thread 수가 절대적으로 성능의 우위에 있게 되는 부분이기 때문에 이 부분에 대해 확인 했습니다


처음에 Stage 에서 2개의 쓰레드(vCPU) 이다 보니 성능이 너무 나오지 않아 운영과 같은 성능으로 업그레이드 되었습니다 그리고 내부에서는 4개의 Node 에서 2개의 Node 만 사용 중이었고 또 내부의 Kubernetes 환경에서는 최소 4 최개 8개의 Pod로 구성되어 있기 때문에 실제로 산정 가능한 Task 의 개수는 8개 내에서 처리 될 것으로 보입니다 (이렇게 AWS 구성에서 성능 수치를 산정하는게 맞을까요? )
즉 분산되어 있는 여러개의 처리기들이 있지만 단일 Macbook 보다 성능이 안 나오는 case 도 가능했습니다 그럼에도 불구하고 AWS의 Kubernetes 환경이 좋을 수 있는 건 AWS 에서 Node 가 사용 가능한 물리적인 성능 수치를 늘리는 것이 쉽게 가능하고 서비스가 커지고 복잡해지면서 관리할 다양한 용도의 네트워크 장비와 서버 들이 온프레미스 환경 보다 편하게 인프라 관리가 가능한 장점들이 있을 것으로 보입니다 장기적으로는 우리의 서비스 히어로들이 각각의 세계관을 가지고 발전되야 하는 모벤저스가 되야 하는 명분이기도 합니다
최소 개수의 자원으로 최대의 효율을 내려는 효율성의 측면을 고민하다보니 조금 무거운 작업이어도 더 적은 회수로 일하는 경우를 가정하게 되었습니다 즉 1번 가설로서 문제에 접근했습니다
가설 1. 최대 개수를 빠른 시간내에 처리하기 위해서는 최소 회수로 최대량을 처리해야 한다 (효율성의 관점)
- 고려할 것 : bulk insert, batch process, max array request, min thread/connection pooling, max network bandwidth, connection timeout
- 논리적인 명분 1. 클라이언트에게 편리한 사용자 경험을 제공 하고 싶음 (최소 요청의 횟수의 경험)
- 논리적인 명분 2. 반복 요청에 의한 예외 핸들링시 원자성의 원칙을 쉽게 처리 할 수 있어야 함(All or Nothing)
- 논리적인 명분 3. bulk/batch application 으로서 처리한다면 대용량 처리를 위한 API 로 처리 가능(DB 처리 시간 총합 최소화)
- 논리적인 명분 4. application 설계상 sender 와 listener 가 분리 되지 않았으므로 다른 API 와 영향도를 최소로 하기 위한 서버 가용 리소스의 최소 사용 (min thread/connection pooling)
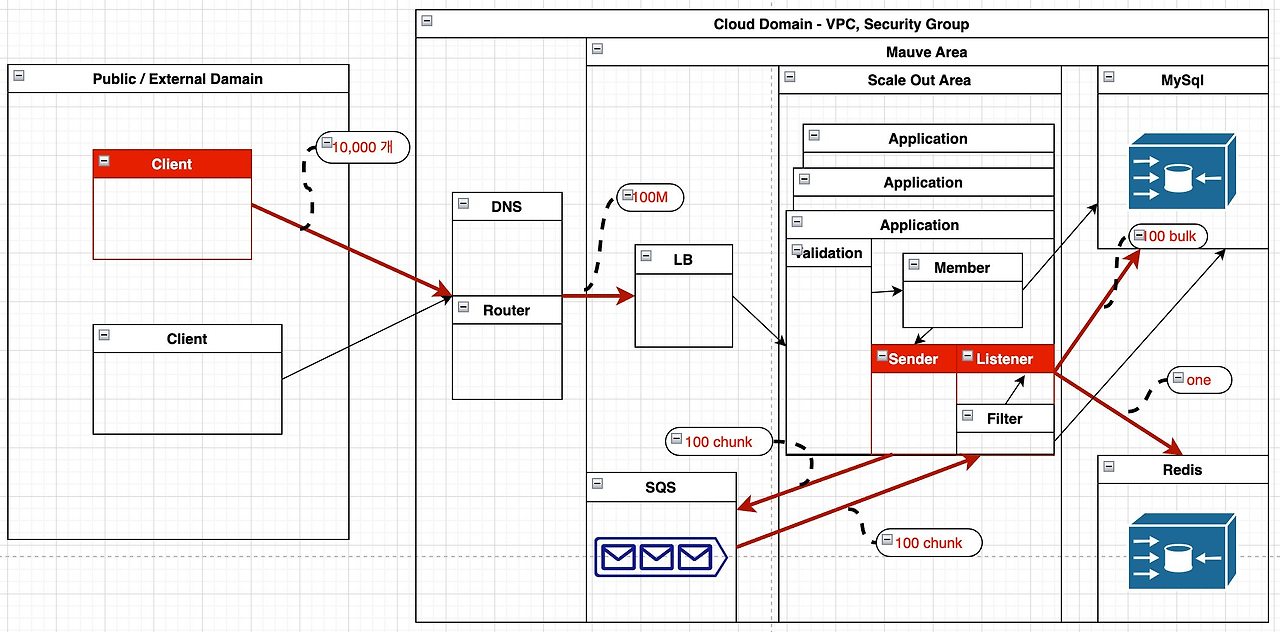
클라이언트로 부터 대량을 한번에 입력받고 Application 에서는 chunk 단위를 크게 잡아 많은 개수를 최소 횟수로 처리하는 방식으로 고려했습니다
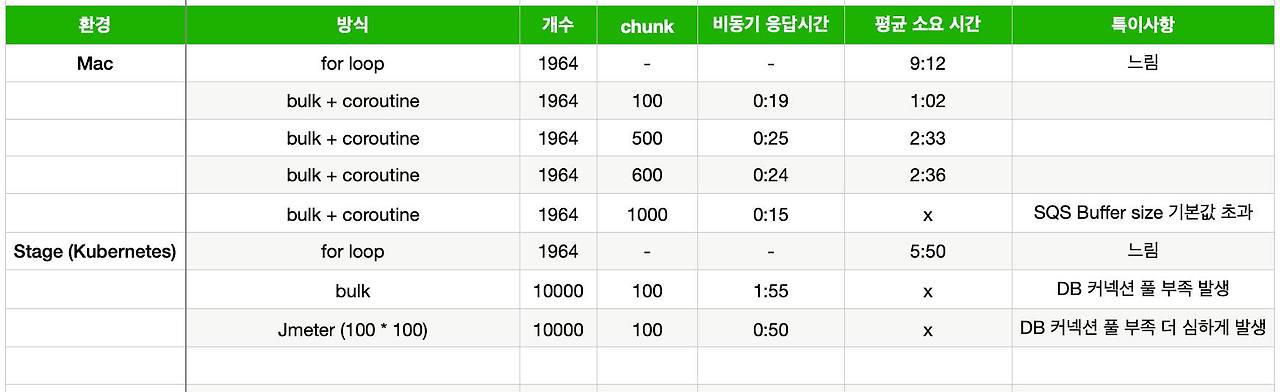
결과는 매우 좋지 못했습니다 Local 환경인 Mac 에서는 약 2000 건 정도가 20초 정도이어서 2,000,000 건 정도가 20000 초 정도면 333분 이면 5시간을 넘어갔고 Stage 에서는 DB 커넥션 풀 부족현상과 Heap Memory 부족까지 발생되었습니다
연쇄적으로 SQS message queue 처리를 못하는 경우도 생겼습니다
Caused by: java.util.concurrent.ExecutionException: java.lang.OutOfMemoryError: Java heap space
[ERROR][org.hibernate.engine.jdbc.spi.SqlExceptionHelper.logExceptions:line142] - HikariPool-1 - Connection is not available, request timed out after 30000ms.
[WARN ][com.zaxxer.hikari.pool.HikariPool.run:line787] - HikariPool-1 - Thread starvation or clock leap detected (housekeeper delta=48s8ms38µs81ns).
[WARN ][org.springframework.cloud.aws.messaging.listener.SimpleMessageListenerContainer.run:line359] - An Exception occurred while polling queue 'sta-mauve-point-standard-queue'. The failing operation will be retried in 10000 milliseconds
com.amazonaws.AmazonClientException: Caught an exception while waiting for request to complete...
at com.amazonaws.services.sqs.buffered.QueueBuffer.waitForFuture(QueueBuffer.java:344)
at com.amazonaws.services.sqs.buffered.QueueBuffer.receiveMessageSync(QueueBuffer.java:258)
at com.amazonaws.services.sqs.buffered.AmazonSQSBufferedAsyncClient.receiveMessage(AmazonSQSBufferedAsyncClient.java:161)
at org.springframework.cloud.aws.messaging.listener.SimpleMessageListenerContainer$AsynchronousMessageListener.run(SimpleMessageListenerContainer.java:336)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.base/java.util.concurrent.FutureTask.run(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.base/java.lang.Thread.run(Unknown Source)
Caused by: java.util.concurrent.ExecutionException: java.lang.IllegalStateException: Connection pool shut down
at java.base/java.util.concurrent.FutureTask.report(Unknown Source)
at java.base/java.util.concurrent.FutureTask.get(Unknown Source)
at com.amazonaws.services.sqs.buffered.QueueBuffer.waitForFuture(QueueBuffer.java:327)
... 8 common frames omitted
Caused by: java.lang.IllegalStateException: Connection pool shut down
at org.apache.http.util.Asserts.check(Asserts.java:34)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.requestConnection(PoolingHttpClientConnectionManager.java:269)이 밖에 몇가지 사실을 더 알게 되었는데 지난번 코틀린에 대한 글처럼 JPA는 대용량 데이터에 대한 처리로는 적합한 선택이 아니었습니다
MySql 상에 Auto Increment 로 PK 가 설정된 상황에서는 JPA의 bulk insert 기능이 되지 않습니다
대용량에 대한 대안으로 Requery 라는 다른 방식이 소개 된 것도 있습니다 (or QueryDSL)
저희 파트의 정훈님으로 부터 LB의 허용가능한 용량이 100M 라는 부분도 알게 되었습니다
for loop 로는 대량 처리가 시간내에 불가능하기 때문에 coroutine 이라는 경량 쓰레드 활용 방식도 적용했습니다
coroutine 자체만으로도 하고 싶은 말이 많은 부분이기 때문에 일단 과감히 skip 하겠습니다 결국은 이 부분에서 추가 공부가 필요했고 지금도 진행하고 있습니다
적어도 프로세서 / 멀티 코어 / 멀티 프로세스 / 멀티 쓰레드 / 멀티 코루틴(no context switching) 에 대한 개념이라도 잡으려면 아래 영상 보는걸 추천 드립니다 (+ 동시성/병렬 처리 차이)
Bulk Insert 로 대량 데이터를 취급하는 것을 Message Queue 를 chunk(100~1000) 개로 나누어 처리하는 부분은 SQS로 전송까지는 되었으나 SQS Listener 로 처리하는 것이 불가능해졌기에 실패로 돌아가서 다시 처음부터 고려해야 했습니다 (SQS 도 공부해야 합니다)
대량을 한번에 간단하게 처리하는 방식이 일반적으로 bulk 와 batch 처리로 하기 때문에 Message queue 방식에 적합한지에 대한 의문을 가졌습니다
아예 최소량을 가장 빨리 처리해서 즉 1개를 아주 빨리 처리한다면 connection pooling 을 아주 빨리 회전시킨다면 SQS 와 통신구간이나 Database 통신구간에 병목이 상쇄될 수 있지 않을지에 대해 고려 했습니다
가설 2. 분산 처리가 가능하고 스케일 아웃이 가능하므로 가장 빨리 처리하는 방식 즉 응답시간 최소화를 만든다 (최소 시간의 관점)
- 고려할 것 : effective insert, effective array request, effective thread/connection pooling, effective server(pod) count, latency time, processing time, exception handling
- 논리적인 명분 1. 실패에 대한 100% 보장을 할 수 있다면 클라이언트의 사용자 경험이나 예외 처리에 대해 고민할 이유가 없음 (Dead Letter Queue, Guarantee/Validation Processing)
- 논리적인 명분 2. 스케일 아웃에 대한 부담이 스케일 업 보다 적음 (Increase Worker)
- 논리적인 명분 3. 중간에 메시지 큐를 사용해서 완충 장치를 뒀기 때문에 큐로 넣는 Latency Time 만 고려하면 됨 (Fast Response)
- 논리적인 명분 4. 다른 API 와 같은 네트워크 구간을 사용 중이기 때문에 최대 용량을 사용할 수 없고 모든 자원을 적립 비즈니스에 올인 할 수 있는 것이 아니기 때문에 최소 자원의 최대 효율이 필요 함
- 논리적인 명분 4. 막상 테스트 해보니 pooling 사용에 대한 반납이 빠르다면 pool 의 총량에 대해 고민할 이유가 없음 즉 반납 못하고 오래 붙잡는 pool 사용이 문제이지 pool 자원은 최대한 많은량을 빨리 사용하는 방법을 추구해야 함
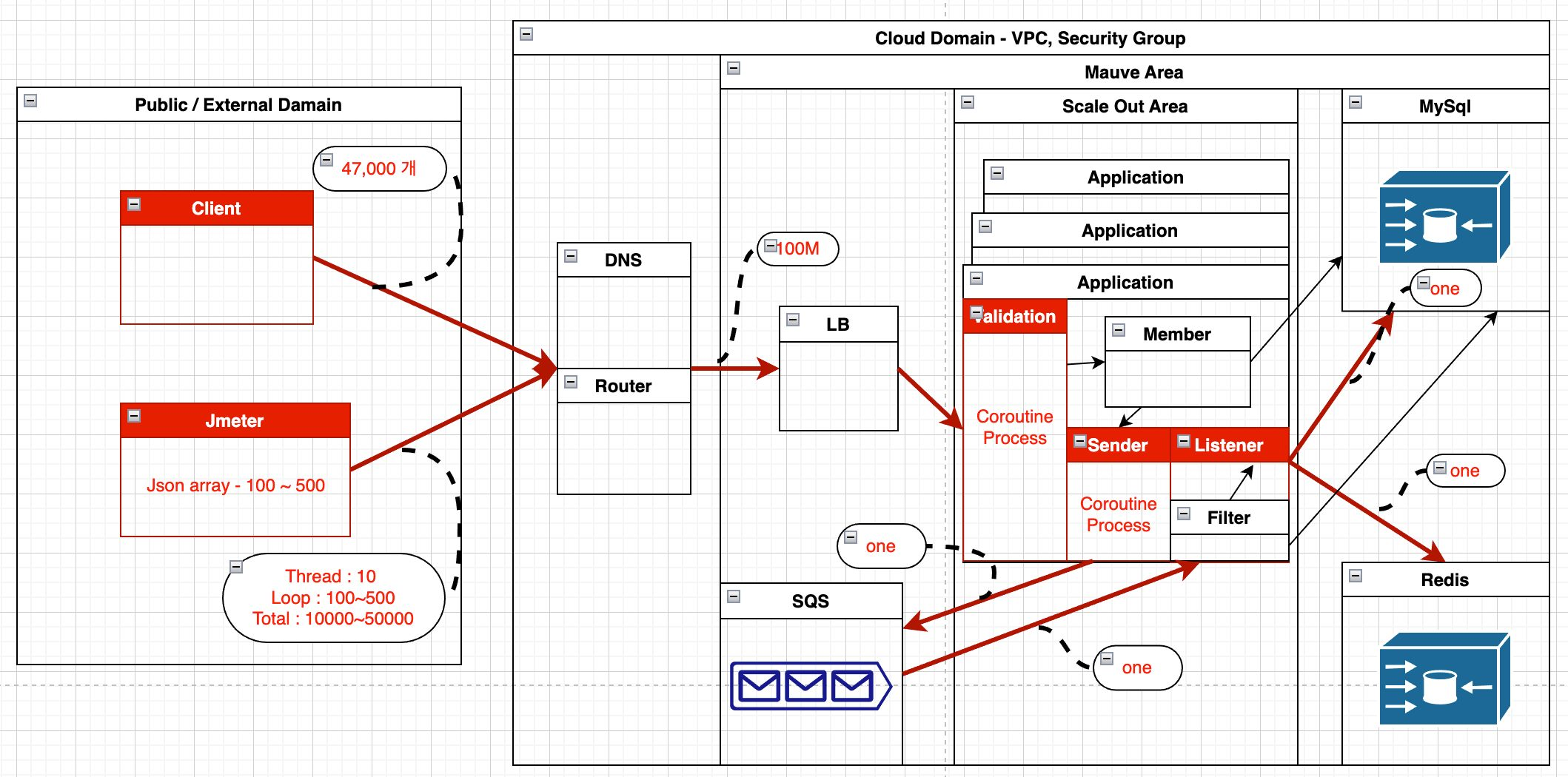
Validation 처리 부분도 For loop 에서 Coroutine 생성해서 동시성 처리하는 방식으로 변경했고 SQS 전송도 한 건으로 변경처리했습니다
대량(47,000) 을 한번에 보내는 경우와 Jmeter로 반복하는 경우로 수를 더 늘려서 테스트를 해봤습니다

결과로 얘기하면 Macbook 에서 47000 개를 한번에 보냈을 때 SQS 전송에만 약 1분 45초 정도로 처리가 되었고 리스너 이후 처리는 Mavue 에서 100% 보장할 부분이라 아무래도 하나씩 처리하다보니 속도가 느렸지만 문제는 없었습니다
스테이지에서도 한 건씩 처리해야 하니 아무래도 Bulk Insert 보다는 많이 느리겠지만 가장 문제가 되었던 Connection 문제가 발생 되지는 않았습니다
꼭 발생될 것이라 보장 못하는 인위적이기는 했지만 10개 Thread 로 병렬식 요청을 보냈을 때는 50만건이 20분 처리도 되어 가장 처음 요구사항인 100만건 30분 정도에 근접했습니다
단순 테스트 이긴 했지만 대량을 처리하면서 단 한번의 오류도 안생기고 가장 고무적인 결과였습니다
하지만 단순히 클라이언트에 완료 응답뿐이고 실제로는 백그라운드에서 엄청 열심히 Listener 가 일하고 있는 상황이고 실제 50만건을 Queue 에서 빠지는 시간을 재보니 거의 하루 종일 작업을 했습니다 (수 시간 걸림)
이렇게 되면 결국 최종 완료 처리가 너무 늦기 때문에 실시간 처리로는 불가능하고 지금 같은 구조에서는 다른 API 도 같이 한 몸에서 동작해야 하기 때문에 운영에 있어 적립에 거의 몰빵하게 되는 불상사를 가지게 됩니다
좀 더 결론을 지어 보자면 가설 1은 connection 부족이라는 상황이 발생되어 장애 현상으로 실험 자체가 성립이 되지 않는 상황이 되었습니다
가설 2는 Queue 로 coroutine 을 대량으로 만들어 동시성 처리를 하고 단순히 queue 로만 보낸 결과로 보면 대기시간에 있어 나쁘지 않은 결과이지만 시스템 전체 완료 처리까지 너무 오랜 시간이 걸려 결국 서버 부하로 인해 다른 모든 API 에 장애가 생길 수 있는 위험한 상태를 유지하게 됩니다
응답시간(Y2) = 대기 시간 (Latency Time) + 처리 시간 (Processing Time)
대기시간은 개선되었지만 처리시간 에서 문제가 되는 상황입니다
하지만 여기서 더 테스트를 진행하는 것은 의미가 없다는 결론을 내렸습니다
그 이유는 지인이 준 결과 값에서 생각하게 되었는데요
- N 사 커머스 쪽에서 REST 처리 기준 단일 array 500 * 2000 반복 횟수로 1,000,000 건 기준 2~3 분 처리 됨
카프타 파티션 30/ 컨슈머 30 운영 기준디비는 분산 디비를 사용
파티션 개념은 SQS 와 Queue 내부적인 구조 차이가 있을 수 있어 이 부분은 일단 차치하고 분산 DB의 경우도 Mauve 적립 프로세스 자체가 Auto Increment index 로 append 만 되는 관점이기 때문에 애초에 update나 delete 가 없는 정책상 Table의 Lock 과 분산 DB 의 동기화와 같은 서로의 시스템에 대한 이슈들이 있기에 큰 문제가 될거 같지 않아 이 부분도 영향도에서 제외했습니다
다만 컨슈머 즉 Listener 역할을 하는 녀석이 30개이고 여기에 2core 식만 지정이 되어도 60개 정도의 Thread 자원을 사용할 수 있는 얘기가 되는데 현재로서는 4core의 2개 Node에서 분산 처리한다의 관점이 마른 행주에 물짜내는 수준으로 보여 애초에 대량 처리에 대한 총 용량을 줄이거나 아니면 AWS 운영 성능 Spec 을 올리는 것이 필요하다는 생각입니다
이 부분은 비용의 관점이기 때문에 실제 이 기능이 필요해지는 순간에 유연하게 고려해보고 그 상황전에 모의 테스트를 확실히 하면 될 것 같습니다
더 필요한 부분은 설계상 결합도를 낮추는 부분이 필요하다고 판단되었습니다
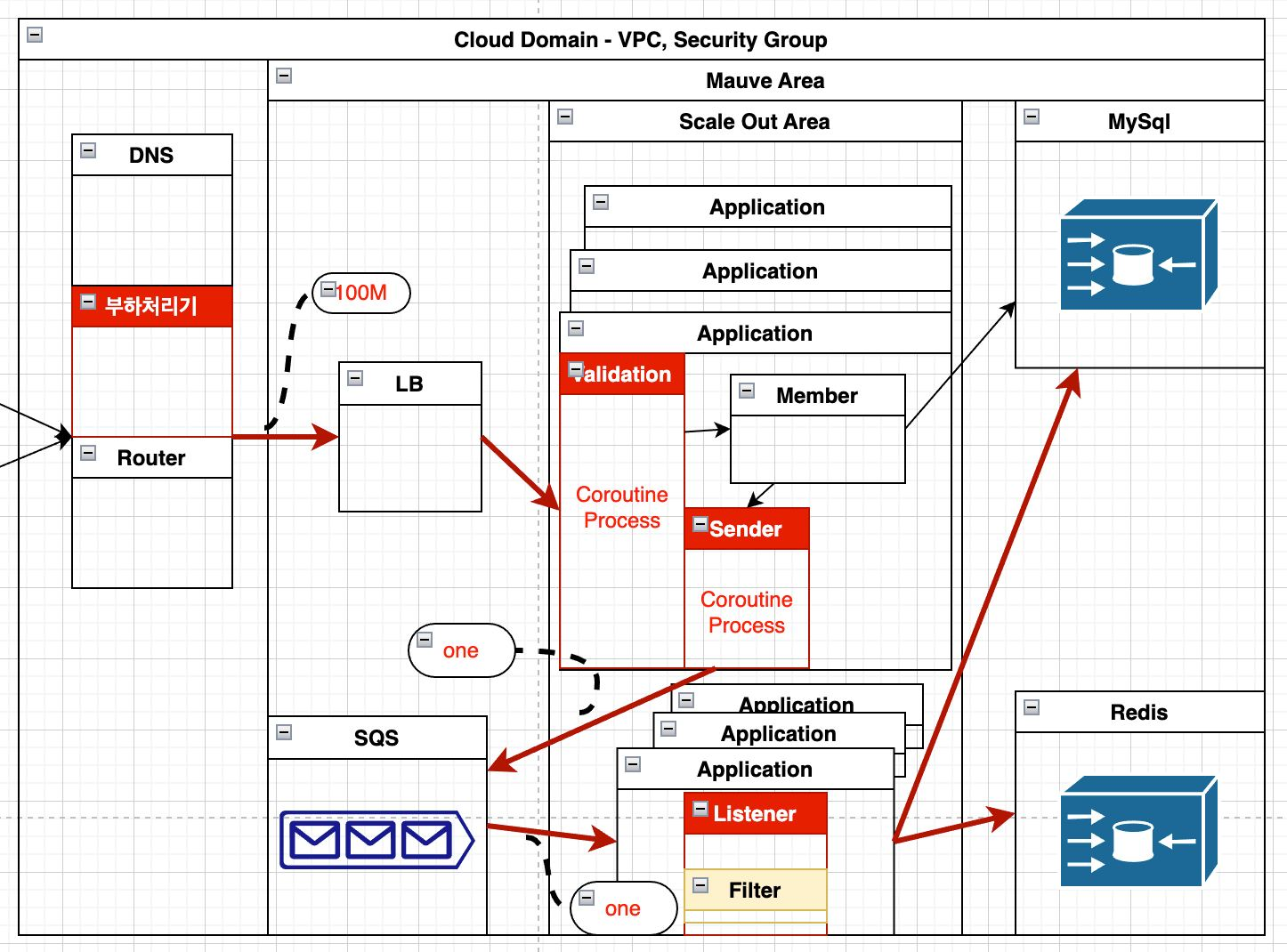
기존에 혼재되어 있던 Listener 에 대한 부분을 분리하고 요구조건에 따라 Flexible 하게 조절을 할 수 있는 Service Worker 로서 현재는 Sender 수와 Listener 수가 동일한 상황이 아니라 요구 입력에 따라 Listener 만 더 확장할 수 있고 상황에 따라 vCPU에 대한 가상 자원도 더 분배해서 쓸 수 있다면 bulk 입력이 없어도 일꾼빨로 엄청 많은 적립 포인트를 처리할 수 있어 보입니다
SQS에서 FIFO 순서가 보장되지 않으면서 중복으로 입력이 들어올 수 있는 부분이 있어서 Application 내부에서 Filter 처리를 하면서 Database에 PK로 AWS의 uuid 를 처리하면서 괴상한 병목구간이 있었는데 이 부분도 Mauve 에서 자체적으로 만드는 uuid 로 unique를 보장할 수 있게 되었습니다

one point Mauve uuid = one SQS service request
이 부분이 보장이 되기 때문에 괴상한 병목구간을 제거할 수 있고 만약 중복 포인트 적립이 들어오면 uuid 의 unique 제약조건에 의해 insert 실패가 발생됩니다
가장 좋은건 DB에 가기 전에 애초에 쳐내버리면 좋겠는데 이를 처리할 Proxy Server 를 두는 것은 또 하나의 네트워크 구간이므로 여러 해결방안을 고민해볼 사안입니다 (AWS 같이 엄청 뛰어난 개발자들의 집합에서 이걸 왜 방치할가요...)
대용량 처리가 들어온다는 부분은 상황에 따라 네트워크 적인 부하가 발생된다는 부분이므로 이를 제어할 처리율 제한 장치를 앞에 두는 것도 고려해봐야 합니다
기본적으로 DDoS 공격이나 Client의 생각없는 무한 요청을 미리 쳐낼 수 있는 부분에 대해서 LB나 Gateway 계층에서 부하 처리기를 두고 처리율 제어가 필요합니다
어느 정도 정리가 되었으나 아주 나이스하고 여러 한계상 진짜 멋있는 결과를 가져오지는 못해 아쉬운 부분도 많습니다 다만 분산처리에 대한 고민과 대용량 처리에 대한 고민들을 시작할 수 있는 계기는 되었던 것 같습니다 (여러 시행 착오들을 통해)
결과와 별개로 획득한 다양한 경험 조각들을 보면 아래 내용들이 있는데 관심있는 부분을 골라 보셔도 좋을 것 같습니다
- 성능 분석이란 이런 것 (사실 아래 내용에 감명받았습니다)
- EntityQL의 발견 (Auto Increment 상에서 Bulk Insert가 가능한 오픈소스)
- Exposed 로 JPA 탈출하기 (대용량 데이터 다룰 경우)
- JPA Bulk
- Coroutine 을 더 잘 쓰기위한 (비동기 동시성 프로그래밍을 위한 Spring Webflux)
- 배달의 민족 세미나 - 토비 개발자의 스프링 리액티브 프로그래밍
- Q. NodeJS (Promise / Async / Await)가 있는데 굳이 스프링 리액티브를 써야하는지? 란 질문이 있음 (Webflux 구조를 보면 어 이거 NodeJS 구조랑 같은거 아냐? 라는 동일한 질문을 하게 되었습니다)
- 스프링 blocking vs non-blocking : R2DBC vs JDBC & WebFlux vs Web MVC
- How to Fire and Forget Kotlin Coroutines in Spring Boot
- In the Spring world, coroutines are supported at a framework level by Spring WebFlux, the non-blocking alternative to Spring Boot. In Spring WebFlux, controller methods can be declared suspend.
- 배달의 민족 세미나 - 토비 개발자의 스프링 리액티브 프로그래밍
- Hickari Connection Pool
- Tomcat Thread Pool
- Coroutine
결국은 Spring Boot Web MVC 가 아닌 Webflux 로 가는 부분이 필요해보이는데요 단순히 이게 새로운 것이라서 좋다가 아니라 더 자원을 효율적으로 쓰는 방법을 고민한 개발 방법입니다
자원을 더 효율적으로 써야 하는 이유는 많은 양의 데이터와 트래픽을 고민한 서버를 이제 만들 시기와 오고 있는 부분입니다 (물론 모든 환경이 다 큼직큼직한 그런 건 아니지만 제가 처음 모바일 네트워크를 1G 데이터 사용하던 것에서 결국 무제한으로 오듯이 데이터와 트래픽은 점점 많아질 가능성이 많아 보입니다)
계속 얘기하다가는 끝이 없을 것 같아.. 일단 여기서 Stop 하고 다시 또 필요한 부분에서 파고들려고 합니다
이것을 쓰는 중에 싱어게인 2를 보게되었는데 거기에 어떤 가수인지를 쓰는 곳이 있었습니다

제가 계속 Backend 개발자로 그 분야로 이 일을 한다면 어떤걸 해야 하지? 라는 생각을 한 적이 있는데 결국 데이터와 성능으로 생각이 많이 되었습니다
비장함을 각오로 아래로 바꺼봤습니다

같이 스터디 관심 있으신분 찾고 있습니다
- 비동기/논블럭킹 프로그래밍에 대한 관심
- 더 좋은 서버 구조 아키텍처에 대한 관심 (인프라는 아직 잼민이입니다..)
- 더 이상 Hello World 가 코딩의 시작이 아닌 @Test 가 먼저 하는 방법에 대한 관심
- 단위/통합 테스트가 뭔지에 대한 관심
- 인증/회원/보안 서비스에 대한 관심
- 기타 등등 토론하고 싶은 모든 것들 (리팩토링 2판 포함..)
내용이 매우 길고 장황했는데.. 그래도 저와 비슷한 고민을 하게 되거나 비슷한 문제에 직면 했을 때 처음 접하는 부분이 있다면 조금이나마 도움이 되길 바랍니다 (혹은 이상하거나 잘못된 부분 있으면 수정 사항알려주세요~)
'My Work > Tech Blog' 카테고리의 다른 글
| Ktor를 써 봤습니다 (0) | 2025.10.12 |
|---|---|
| Ktor 써도 될까요? (0) | 2025.10.12 |
| 코프링 24 시간 안에 끝내기(+ 비동기 프로그래밍) (0) | 2025.10.12 |
| 고객센터 오픈소스 모니터링 구축기 (0) | 2025.10.08 |
| Java 8 이후의 Heap Memory 구조의 변화 (0) | 2025.10.08 |