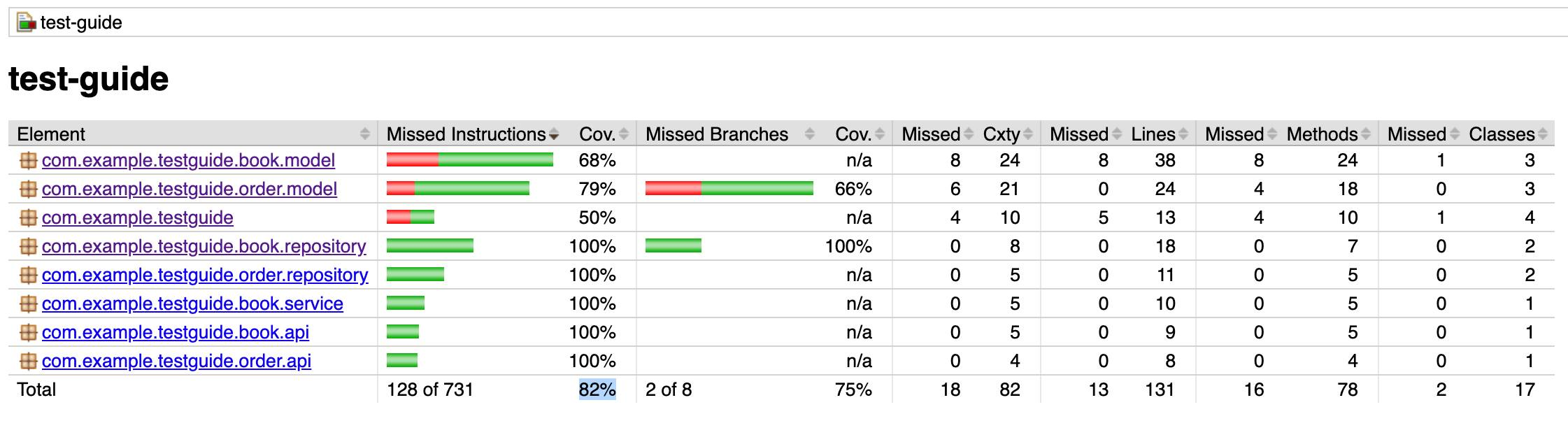
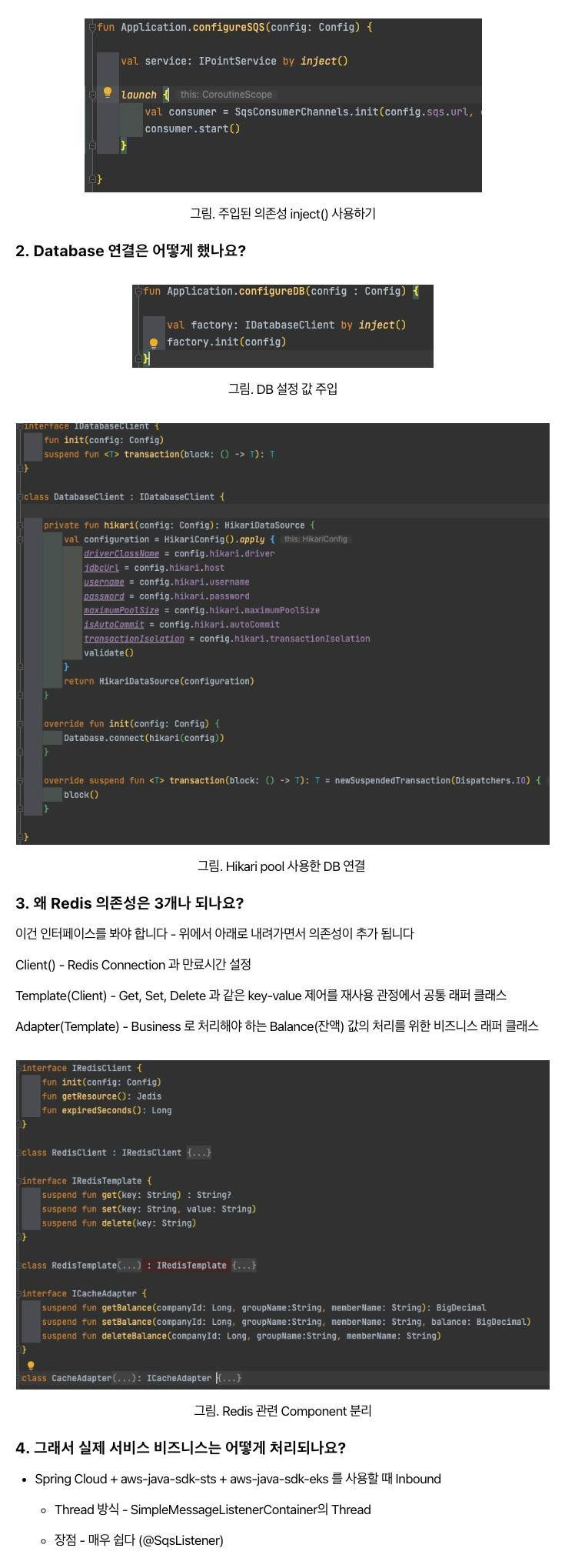
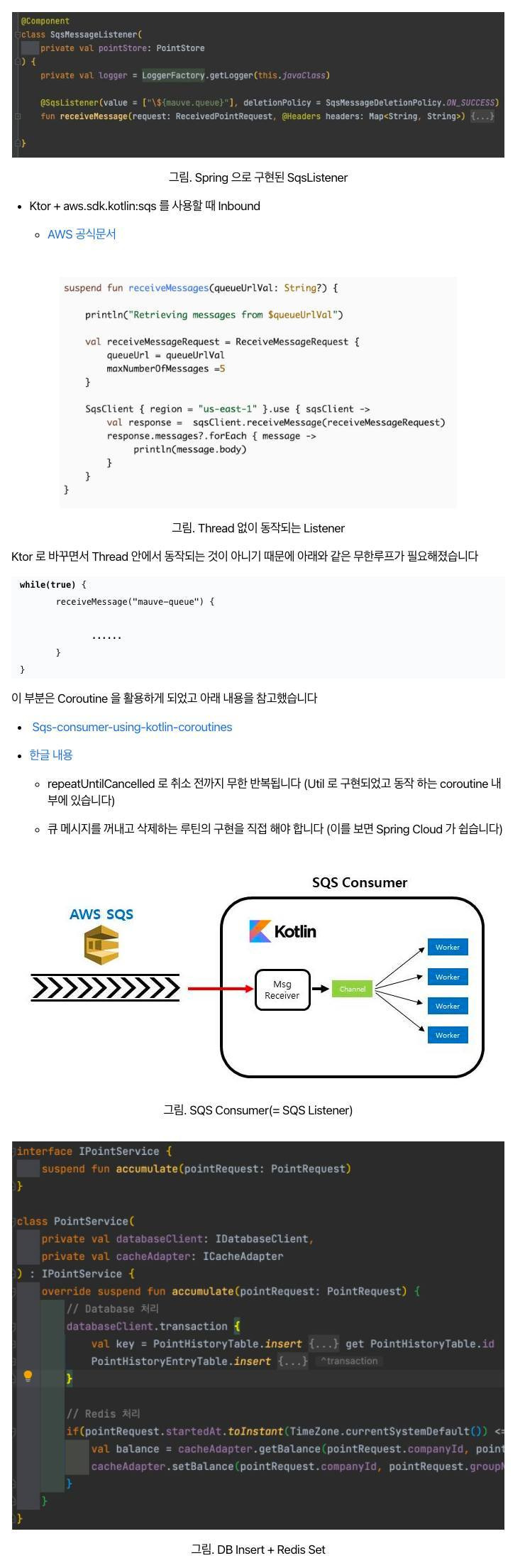
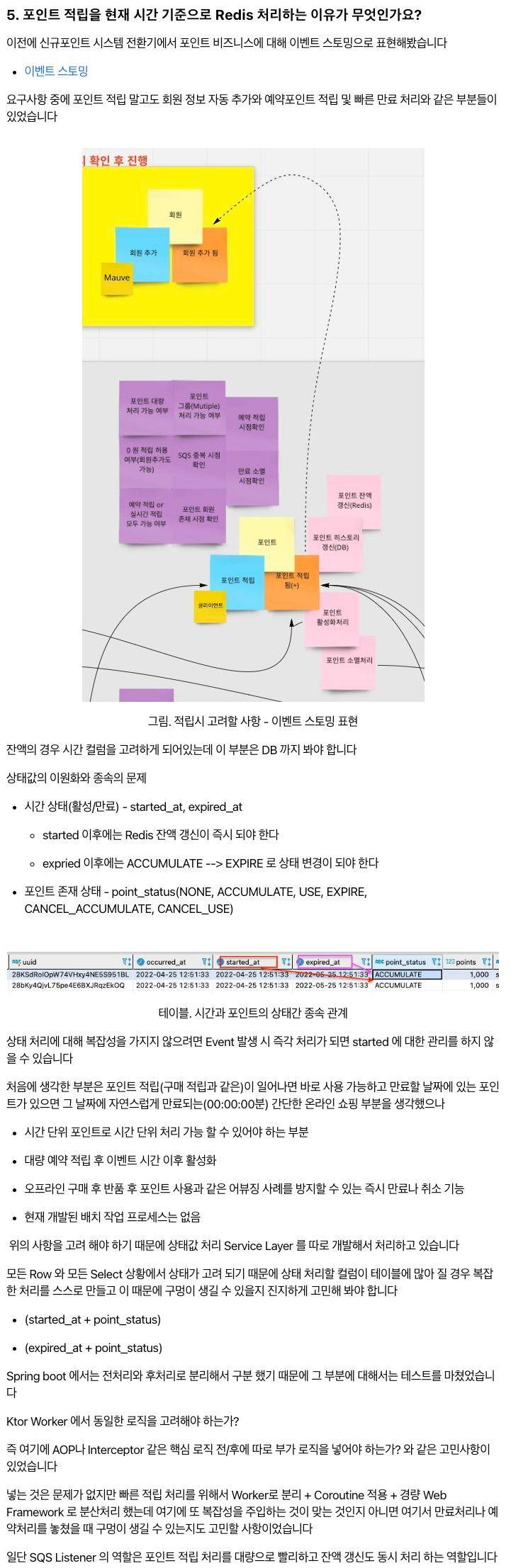
Embulk 는대용량 ETL 작업을 위해 사용하는 오픈소스 솔루션입니다
특징
- 플러그인 형태로 여러개의 소스와 타겟을 지원합니다
- Maven 및 Ruby gem 리포지토리에서 릴리스된 플러그인
- 스키마 예측 (Schema guessing)
- 입력 데이터를 보고 자동으로 입력 데이터의 스키마(테이블 구조)를 예측합니다
- 일일이 설정을 하려면 귀찮은 일인데 자동으로 스키마를 인식해주어서 설정양을 줄여줍니다
- 빅 데이터 세트를 처리하기 위한 병렬 실행
- All or Nothing 보장하는 트랜잭션 제어
왜 필요한가?
- 데이타 분석에 있어서 아키텍쳐적으로 중요한 모듈중의 하나는 여러 서버로 부터 생성되는 데이타를 어떻게 모을 것인가 입니다
- Embulk는 대량 데이터 로더입니다. databases, storages, file formats, cloud services 등의 유형 간의 데이터 전송을 돕습니다
- ex: Bigquery, Oracle, MySQL, PostgreSQL, CSV, JSON…
어떤 개발자가 만들기 시작했을까요?

구조로 표현하면 아래와 같습니다


ETL 이란? (Extract, Transform, Load)
추출(Extract), 변환(Transform), 적재(Load)
예시) calendar라는 테이블에 년/월/일/시/분/초 형태로 가 컬럼이 존재합니다. 이러한 데이터를 사용해서 통계를 내는 어떤 프로그램을 실행하려고 확인 했더니 해당 프로그램은 년월일/시분초 와 같은 컬럼형태를 요구하고 있을 때
아래와 같은 작업을 하는 경우를 ETL이라고 합니다
1. 기존 테이블의 데이터 추출(Extract)
- 대상이 되는 calendar 테이블에서 년/월/일/시/분/초 형태의 데이터를 전부 추출
2. 추출한 데이터의 변환 (Transform)
- 추출한 데이터를 요구하는 형태인 년월일/시분초 형태로 변경
3. 추출 및 변환한 데이터의 적재(Load)
- 변경이 된 데이터를 새로운 테이블에 적재
간단하게 정의 해보자면 “한 곳에 저장된 데이터를 필요에 의해 다른 곳으로 이동하는 것”, "저장된 데이터를 변형하여(요구사항에 맞게) 다른 곳으로이동하는 것" 입니다

ETL 구조
Source - Target 구조

Embulk 로는 이관하는 것이 가능하지만 모든 Job 들을 관리하는 것은 되지 않습니다
이 부분을 보완해주는 툴로는 Digdag 을 사용하고 있습니다
Data Workflow Management Tool을 쓰는 이유는?
데이터를 추출, 가공, 저장 하는 ETL(Extract, Transform, Load)등을 진행하다보면 여러개의 일들이 연결되어 수행되는 경우가 필연적으로 발생됩니다
여러개의 일들이 연결되어 수행 하는 동작하는 동작 흐름(Workflow)을 실행시키기 위해 배치 형태의 테스트를 실행 , 에러 분기에 따른 알림 , 재실행을 시켜주는 도구의 요구사항이 생기게 되었습니다
이러한 이유들로 인해 Data Workflow를 편리하게 실행시키고 관리하는 자동화 도구로 Airflow , Luigi , Digdag , Oozie)들이 등장하게 되었습니다

오픈소스 workflow 관리 도구들
- 선언형: XML이나 YAML과 같은 서식으로 기술
- 스크립트형: 예를 들면 파이썬과 같은 스크립트 언어로 기술한다
Digdag 란?
Digdag는 복잡한 작업 파이프라인을 구축, 실행, 예약 및 모니터링하는 데 도움이 되는 간단한 도구입니다.
태스크가 순서대로 또는 병렬로 실행되도록 종속성 해결을 처리합니다.
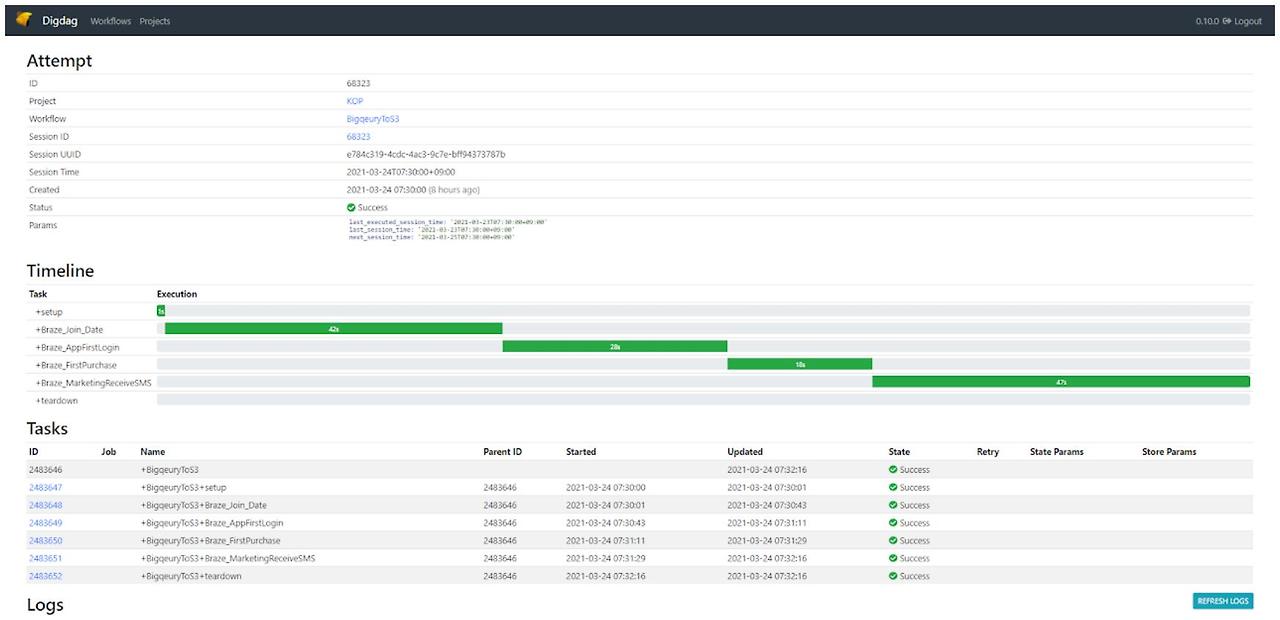
digdag workflow ui
진짜 중요하다고 생각하는 이유는?
우리가 운영하는 모든 데이터 플로우는 태스크로 지정되어 실행하는 도중 실패할 수 있기 때문에 이를 인식하고 재시도하고 관리하기 위해 필요합니다 즉 Workflow를 필수적으로 모니터링 할 수 있어야 합니다
- 태스크의 정기적인 스케줄 실행과 결과 통지
- 태스크 간의 의존 관계 정의와 정해진 순서대로 실행하기
- 태스크의 실행결과를 영속적으로(필요하다면 DB로) 보관하고 오류 발생시 재실행 하기
그리고 복구를 위해 재실행할 때는 동일 태스크를 여러 번 실행해도 동일한 결과를 만들어야 하기 때문에 상황에 따라 멱등성을 이끌어 내야 합니다
- 테이블을 삭제한 뒤 다시 생성하는 것 처럼 태스크를 여러번 시도해도 실패하거나 이미 들어간 데이터로 인해 시스템에 문제가 없어야 합니다
필수적으로 대용량 데이터를 다루는 부분이기 때문에 매우 중요하고 절대적으로 동작이 365일동안 무중단으로 장애없이 유지되야 합니다
아래 그림으로 RDS에서 BigQuery로 데이터 이관 구조를 표현할 수 있습니다

Digdag 구조
해당 시스템의 구조나 중요도는 설명했으니 이제 본론으로 들어가서 비즈니스 적으로 협업을 하기 위한 방법에 접근해야 합니다
이 시스템은 다양한 데이터를 모두 다루기 때문에 다양한 비즈니스들이 엮여 있습니다
예를 들면 KOP, CRM, WMS, SCM, Campaign, PILS, EDW 등 연관관계 시스템들의 다양한 Database와 하위 시스템의 데이터들을 이관해야 하기 때문에 Embulk 관리자로서는 각각의 비즈니스에 대해 알지 못합니다
이 부분을 쉽게 파악하기 위해 dig 파일이나 embulk를 실행하는 sh 파일이나 yaml 파일에 규칙을 두어 관리하고 있습니다
프로젝트를 구성하는 디렉토리
- .gitlab : gitlab 관련 md 문서 파일
- add-ons : ruby gem 에 올라가지 않은 자체 개발 customizing 된 plugin 프로젝트들
- embulk-input-redis-restock : input data를 json 형태로 변환
- embulk-output-redis-expires : output data에 expire time 을 지정할 수 있게 함(내재화 진행 중)
- digdag-projects
- digdag-porjects-fnckop
- digdag 스케줄링 된 work flow 에 대해 지정하는 폴더
- .dig 파일들이 모여 있는 곳
- cron 스케줄 시간 지정
- parallel 동작 지정
- 동작시킬 sh 파일 지정
- doc : 메뉴얼 md 문서 파일
- embulk-projects
- embulk 로 실행될 shell script 들이 모여 있는 곳
- 하위에 yml.liquid 파일에 대한 명세를 보관
- in 폴더: In 쪽 Schema 파일
- out 폴더: out 쪽 Schema 파일
- select 폴더: in 쪽 Schema 파일
- filter 폴더: 가공이 필요한 경우 지정하는 파일 (컬럼단위 변환, 개인정보 관련 masking 컬럼 지정)
- GCP : GCP 계정 관련 파일
- lib : 사용하고 있는 Datasource 관련 jar 파일
- etc
- docker 파일
- jenkins 파일
digdag 디렉토리에 비즈니스 명세를 작성
규칙 1. Source To Target 지정
목적 : dig 파일만 보고 해당 작업이 어떤 작업인지 바로 파악할 수 있을 것
digdag 파일에서는 하나의 cron 스케줄로 관리 됩니다
각각의 파일에서는 동일한 시간대의 workflow 가 모이게 되고 같은 방향의 Source / Target 이라도 스케줄에 따라 dig 파일이 구분됩니다
예를 들어 Bigquery To Campaign 이나 Bigquery To Redis 인 경우 시간/일간/월간 스케줄에 따라각각 구분됩니다
하나의 태스크는 테이블 단위로 명령을 수행합니다
명령이 수행되는 파일은 shell script로 작성되어 있습니다
embulk-project 디렉토리에서 동작 파일을 작성
규칙 2. Source 에서 연결할 Target Data Source를 1 : N 관계가 되도록 지정
목적: 현재 구성된 Source 쪽과 Target 을 하나의 폴더에서 관리하고 하위 폴더에서 Target 관련 파일을 관리
Target 디렉토리에서 계정 단위로 파일을 작성
규칙 3. 접속하는 Datasource 계정명으로 sh 파일과 yml 파일을 작성
목적: embulk 관리자는 Database 관리자는 아니기 때문에 어떤 DB 구성을 사용해야 하는지 알 수없어 파일 이름만 보고 바로 알 수 있게 지정
digdag 파일이 어떤 스케줄과 soruce / target 을 알고자 함이라면 어떤 database 구성으로 작업하는 파일인지 또는 상황에 따라 재사용을 할 것인지 바로 알기 위한 목적으로 구성했습니다
위 3가지 규칙으로 embulk 의 비즈니스 개발을 설명해 볼 수 있습니다.
- Source 와 Target database가 무엇인지 알아야 한다
- Source 와 Target 간 어떤 시간 스케줄로 동작할지 알아야 한다
- Source 와 Target 이 어떤 connection 으로 연결되는지 알아야 한다
- 상황에 따라 in / out / select / where / filter 작업으로 테이블 하위 컬럼 단위까지 조작이 필요한지 알아야 한다
결국 embulk 와 digdag 로 협업하려면 해당 정보들이 필요합니다
위의 내용을 바탕으로 Asana ticket을 만들어 봤습니다

Embulk를 운영해보니 오픈소스 기반이고 주로 비즈니스 처리 위주여서 Tool 자체에 대해 직접 코딩을 하거나 하는 부분은 없었습니다 (github에 오픈소스가 있어서 불가능한 부분은 아닙니다)
다만 이렇게 폴더나 파일을 어떻게 관리하지?
해당 비즈니스가 확장되는 부분을 어떻게 표현해야 하지?
이런 문제 해결을 어떻게 해야 하는지 초반 시행착오가 있던 것 같습니다
생각해보니 데이터를 관리하는 프로그래머의 역할과 파일을 관리해야 하는 부분이 별반 차이가 없지 않나? 하는 생각이 드는 것 같습니다
프로그램의 메모리에 접근해서 New로 동적할당을 하거나 List, Set, Map, Dictinary 와 같은 자료구를 만들어서 효율적인 데이터를 뽑아내는 것과 수십 수백개의 연관 파일들을 어떻게 명시하고 관리하는 부분도 프로그래머가 더 연구해야 하는 부분이라는 생각이 들었습니다
Java, Kotlin, C#, C++ 같은 언어를 쓰는 명령형 기반이 아닌 yaml, css, xml 같은 선언형 기반으로 코딩한 경험이 되었다고 보고 있습니다
이런 부분에 있어 더 좋은 방법이 어떤 것이 있고 이런 ETL 또는 데이터 엔지니어링과 관련된 부분은 어떻게 더 잘할 수 있을지 고민해 볼 수 있는 부분이 되어 좋았습니다
References
'My Work > Tech Blog' 카테고리의 다른 글
| 고유 식별자 생성 방법에 대한 여러가지 (0) | 2025.10.12 |
|---|---|
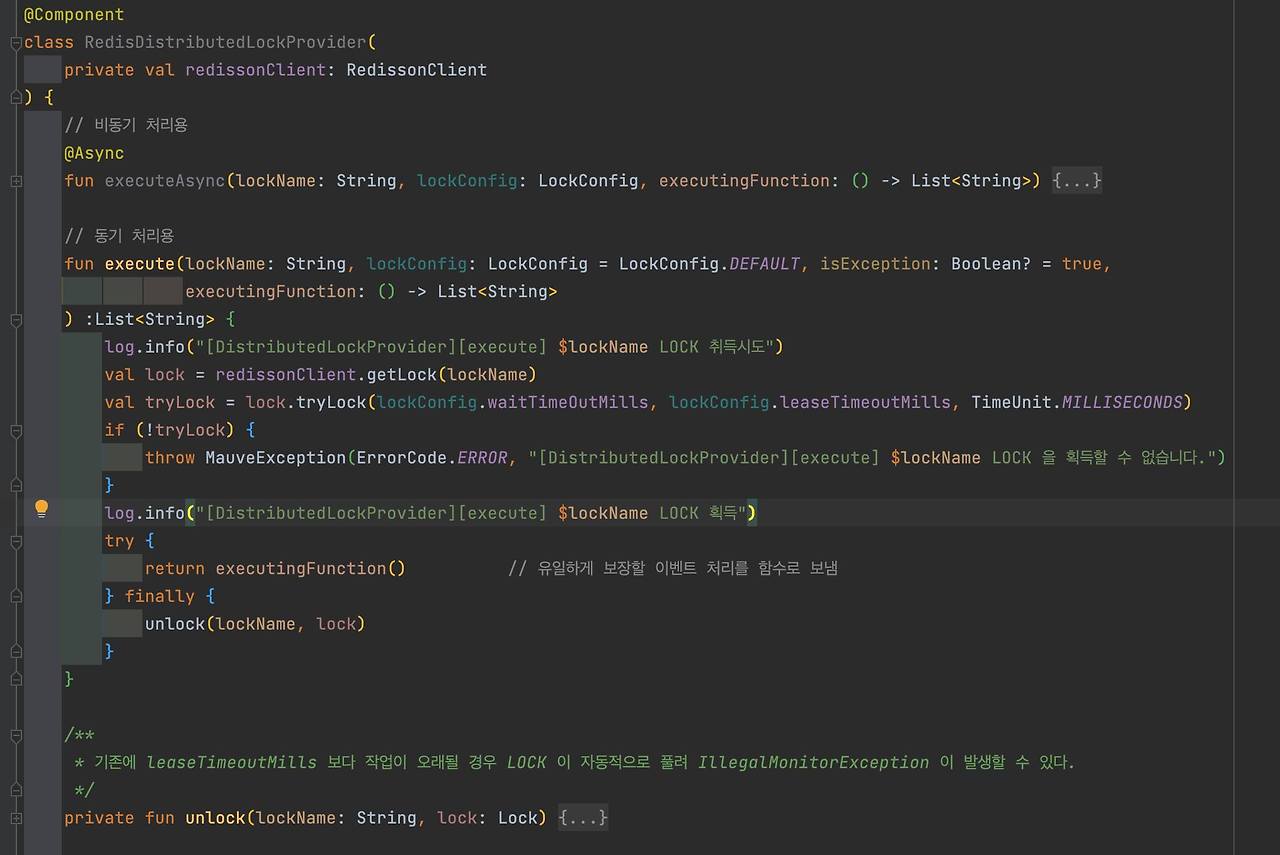
| 서버의 동시성 이슈와 Redis 를 이용한 처리 방법들 (0) | 2025.10.12 |
| CI/CD Overview 스따뜨 (1) | 2025.10.12 |
| Spring Boot 3.0 Release Notes (0) | 2025.10.12 |
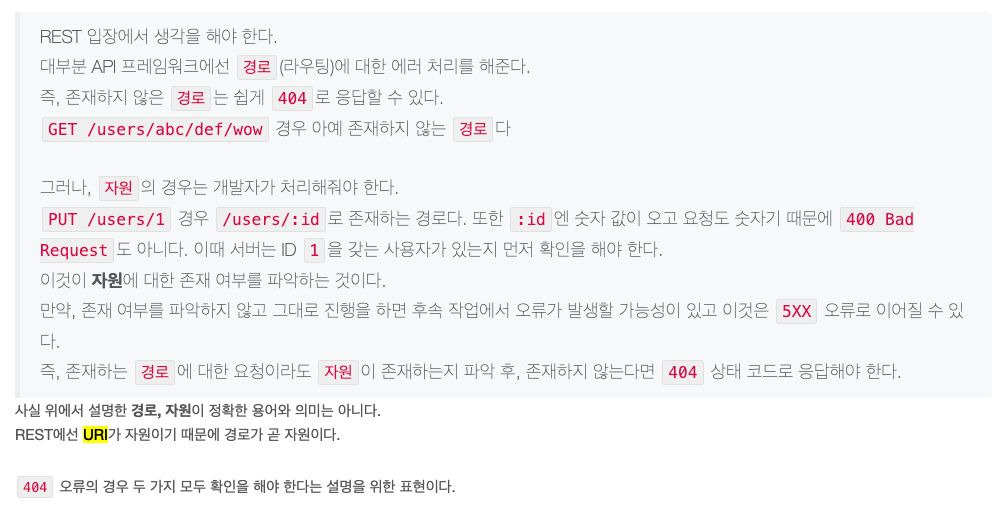
| 서버의 Error 에 따른 HTTP Status Code (0) | 2025.10.12 |